Connecting Elixir to Salesforce (Part 1)
Most of the time we are connecting to Salesforce via an Elixir API server written in Phoenix that receives requests from a Vue.js front-end to send to or retrieve data from Salesforce.

Software is hard. Writing good software is harder. We all know that code should be easy to read, but often times simplifying one area might increase complexity in another. We've seen this problem before. The DRY principle taken too far. Microservices taken too far. How can we refactor our code and systems while still reducing complexity overall?
Instantaneous complexity
The idea that software you read at any "scope" should not be too complex.
This idea is touched on in various software design books, but I'm coining this term to create vocabulary we can work with. You can't tackle a problem until you can first describe it. So what are the scopes?
Software is fractal in nature, in the same way that the human body is made up of systems, organs, and cells.
Software as a whole exists in four scopes:
Being very strongly rooted in Elixir development, I'll use the terms "functions" and "modules", but they are no different from "methods" and "classes".
This is perhaps the most understood complexity problem. We have multiple books and ideas that define what is a "good" function (think Clean Code, ABC Complexity, etc). But the gist is simple: your functions should do one thing.
Do you need a comment to explain a code block? Extract it out to a function instead. Is there a large nasty conditional statement? Make it a function (or multiple). Can you not understand a function at first glance? Break it out into several sub-functions with descriptive names.
If you have trouble at this scope, there's a simple rule of thumb I like to follow: try to write software that a five year old could read.
A fair amount has been written on this subject as well. This is where the term "high cohesion, low coupling" comes into play. We can think of modules as boxes around related sets of functions. So what do we know about "good" modules?
A good module should:
In short, a module should represent one idea.
It's easy to get this wrong when reducing complexity at the function-scope. The most notable example that comes to mind is Ruby on Rails's idea of "skinny controllers, fat models" (many have since realized this is a bad idea).
The goal is to move business logic to where it belongs: in the models. The models themselves become an "actual API" of sorts, while the controllers are simple wrappers on this API to service HTTP requests.
This sounds great in theory, until you have multi-thousand line model files, often littered with tiny functions that are often only called from one place. I like to call these "junk drawer" modules.
So what's the answer to this? Rethinking how you group functions with the command pattern. Is there a complicated task that requires multiple steps? Create a module devoted to that one task, with multiple sub-functions inside.
Some of these modules might get very complex, but the instantaneous complexity is isolated. If you are looking for a "register user" function, you aren't wading through all of the other unrelated functions for a "user"– instead just go find the command file. This has an added benefit of making generated documentation extremely helpful when trying to figure out what a codebase does (just look at the module names).
I like this pattern so much, I wrote an Elixir library for it. It's revolutionized how Codedge structures its projects, and we haven't looked back since.
That said, commands won't be the only modules in your codebase. It is still wise to separate shared functions into well thought out, reusable modules.
A finished project would more likely have these four types of modules:
The next level up, a project (codebase), is a box around a set of modules. Depending on your team's strategy, this can vary wildly. Complexity in a project can range anywhere from extremely simple (microservice) to extremely complex (monolith).
A system is a box around a set of projects, including other services such as databases, load balancers and third party APIs. Like projects, systems can run the full range of complexity.
Anywhere from this:
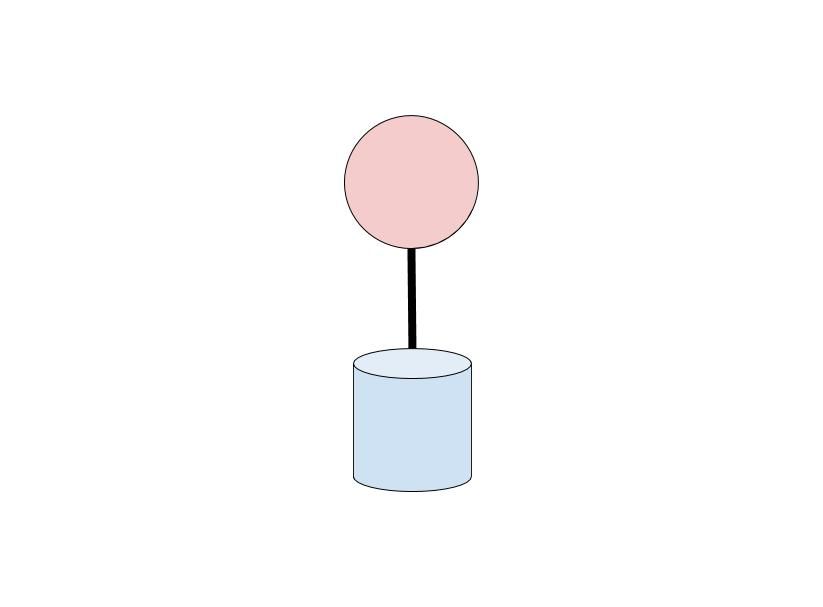
To this:
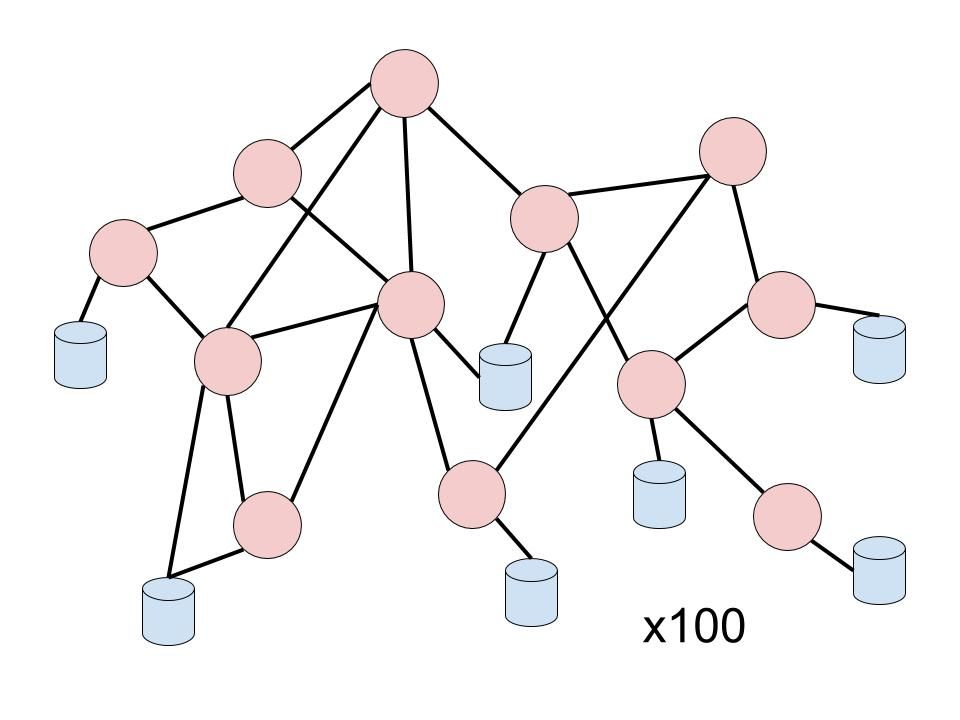
In terms of instantaneous complexity at the project level, microservices are a definite win. Well written microservices can be understood in minutes, but it comes at a cost. You have moved the instantaneous complexity from the project-level to the system-level.
This is the essence of the microservices/monolith debate over the past ten years. "Spaghetti code" in monoliths can exist just as easily in microservices, with the added misfortune of latency issues, API version management, and deployment nightmares (though this point has been made far easier with Docker and Kubernetes).
So what is the answer? Monoliths with well defined boundaries? That can work, but it is very hard to enforce without discipline. Not to mention, there is an enforced homogeneity of the entire codebase that might not exactly align with the requirements of the subcomponents (one primary programming language, one hardware architecture, etc).
Fortunately there is a third option: service oriented architecture (somewhere in between monoliths and microservices).
Instead of one codebase, or a couple dozen, have just a few that are broken along specific problem domains. The instantaneous complexity of the single codebase has been split into a few moderately-complex codebases, without sacrificing simplicity at the system-level. This aligns closely with the essence of Domain Driven Design.
Let's draw on an analogy: a business. It has one "mission", but the people who make up the company have different "roles". Most likely your marketing guys don't know anything about IT, and the operations guys don't know anything about HR. But everyone works together to achieve the company mission, despite specializing in their specific fields.
What does this look like in code? Let's say you have a software application that sells physical products online. You might have a few different codebases along these lines, each one deployed and maintained independently:
Does billing care about product inventory? Generally not, but if it needs to, it can ask via a well-defined API. This is why monoliths can easily become messy. In a monolith with one database, you can simply retrieve the record without asking anyone.
That said, these codebases don't necessarily need to be business problem-specific, but can focus on infrastructure-type roles. A database is also a project, but probably not one you wrote. Your UI may be a separate project (single page applications, mobile apps).
While Elixir Phoenix is a wonderful web framework, at Codedge we don't use it for anything UI-related on the web except in the most basic of systems, such as corporate marketing websites. For anything more complex, we use Vue.js single page applications, built and deployed separately from the API servers it calls out to.
In this way, our frontend and backend developers feel most at home in their respective projects, a strict boundary is enforced between the two domains, and the APIs created can be reused in other projects such as mobile applications. While this does increase overall code, it reduces complexity of each individual project.
It is important to realize that reducing complexity does not necessarily eliminate it. You can't escape it. Complex software will be complex somewhere. Instead you should focus on spreading the complexity across the various scopes to make it more pleasant for everyone.
You can achieve optimal instantaneous complexity by following these guidelines:
You already know where the instantaneous complexity lies in your software. It's the gigantic file that nobody wants to touch. It's the 10-year old codebase that's collapsing under its own weight. Anything that invokes an "Ew." response is a prime candidate.
Let's write better software!